この記事は BBSakura Networks Advent Calendar 2023 の 25 日目の記事です。
こんにちは。BBSakura でソフトウェアエンジニアをしています早坂(@takemioIO|@gtpv2) と申します。
普段はモバイル開発グループという組織でモバイルコアの開発・運用をしていますが、その傍ら技術広報活動もしています。
技術広報に関しては 1日目の記事 で弊社のみずきさん(@n0mzk|@n0mzk.bsky.social)が書いていますのでぜひご覧ください。
そして自分はこのアドベントカレンダーの主宰もやっております。
今年で(学生時代のアルバイトから数えて)3 回目の主宰ですが、なんと今回は誰かが記事を無理やり 2,3 本書かずとも無事達成しました。
今年もBBSでアドカレやります。
— Takeru Hayasaka (@gtpv2) 2023年11月30日
アドカレの主催も3回目にもなると人を集めるのにも慣れたもので、(?)
遂に今年は一人二つ以上の記事をを書かずに済むようになりました。いやー労力が減って嬉しい。
無事完走出来るようにみんなで頑張ります。
ぜひ12月からの投稿をお楽しみに! https://t.co/RkFuA896KE pic.twitter.com/qQESgRGSzR
いやー人が集まらず毎年 2 本は書いていたので嬉しいですね。3 年目にしてやっと達成です。なので今年は頑張ったし 25 日の大トリをもらってもよいだろうということで最終日をもらうこととしました。来年も 25 日を取りたいですね。そして 1 本の記事にちゃんと労力を掛けられることって最高なんだなと思いましたね。
無事最終日を迎えられてホッとしております。
さて、雑談は程々にしておくとして、この記事は最近の MPTCP に関してのあれこれと、マルチパス技術の肝であるスケジューラーを eBPF で書けるようになったんだぜ?みたいな話をする記事です。しばらくお付き合いください。
MPTCPとは
MPTCP(Multipath TCP) とは TCP のマルチパス化技術のことです。MPTCP は任意のインターフェースに紐づく複数の TCP コネクション(以降 subflow と呼ぶ)をバンドルして、通信の帯域を拡張したり、適切なパスを使ったりすることで、通信を最適化する技術です。例えば任意のパスの通信品質が悪くなった時に流す流量を減らして制御したり・違うパスにフォールバックするなど Active Active, Active Standby なパスの使い方が可能です。
MPTCP という技術はちょうど 10 年前(2013 年)に RFC6824 MPTCPv0 として RFC 化されました。現在では RFC8684 MPTCPv1 と呼ばれるものが現行の最新です。Linuxカーネルのサポート も 5.6 から v1 のサポートに切り替わりました。
MPTCPスケジューラーとは
MPTCPスケジューラーとは、利用している subflow に対してどれくらいパケットを投げるかを決定するために使われます。
例えば A の subflow(A の Interface を持つパスと言い換えても良い)の調子が悪くなったので B の subflow に流量を増やしたりするのはこのスケジューラーのアルゴリズムで決定されます。
このスケジューラーには BLEST1というアルゴリズムをベースにしたのが現在の Linux のデフォルトで使われていたり、他にも Round-Robin や Lowest-RTT-First2など利用するアプリケーションの最適化戦略によって様々なアルゴリズムに変更可能なことが知られています。
最近の MPTCP を取り巻く環境の話
前述した通り MPTCP 自体は RFC 化から約 10 年の歴史があるのですが、現在ではどれくらい使われているのでしょうか。
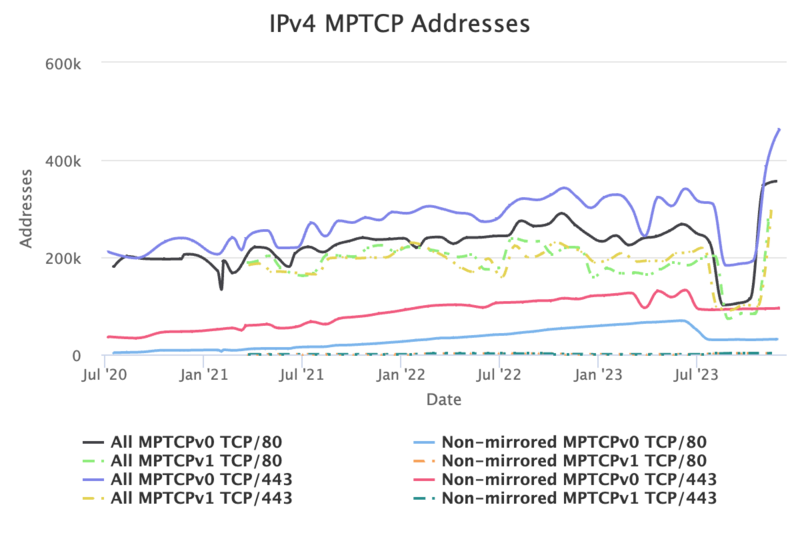
Multipath TCP Measurement Service3という論文を眺めてみると、数年で 20 倍に増加したという話が書かれています。
この論文を書いた人たちは ZMap を利用して IPv4 の空間全体と IPv6 Hitlist4を使って IPv6 の一部を現在も計測していて、その計測データを mptcp.io というサイトで可視化しています。
IPv4 を見ると現在では MPTCPv0 を 80 番 ポートで動かしているのは 400k Addresses を超える程に達しました。
MPTCP を取り扱うための整備も進み、Linux では MPTCPv1 を前提にした mptcpd というデーモンも実装されています。
これを利用することで path management を行うことができます。更に付随している mptcpize コマンドラインツールを使うと TCP を利用したアプリケーションを書き換えやリビルド等の変更を実施せずに MPTCP を活用できます。
実際に TCP に対応した iperf3 で使うと以下のようになります。
mptcpize run iperf3 -s
これは 、LD_PRELOAD 環境変数を使い glibc をオーバーライドすることで実現しています。そのためアプリケーションの更新は不要になります。Go 言語では glibc に依存させずにビルドが可能です。このケースでは当然ですが環境に依存しない故に動かすことができません。
最近では Go言語v1.21のパッケージの中でMPTCPサポート が入るようになりました。以下のように書くだけで MPTCP 対応が完了するようになりました。これによって Go でも(リビルドは必要ですがほぼ)TCP と同じ利用方法で使えるので簡単に MPTCP が使えて便利だなと思いました。
lc := &net.ListenConfig{}
lc.SetMultipathTCP(true)
ln, err := lc.Listen(context.Background(), "tcp", *addr)
利用用途としても最近では非常に発達しています。よく知られてる Appleの利用例 以外にも OpenMPTCProuter というプロジェクトでは複数の回線を束ねて帯域を広げるのに MPTCP を利用したルーターを作ったりしています。
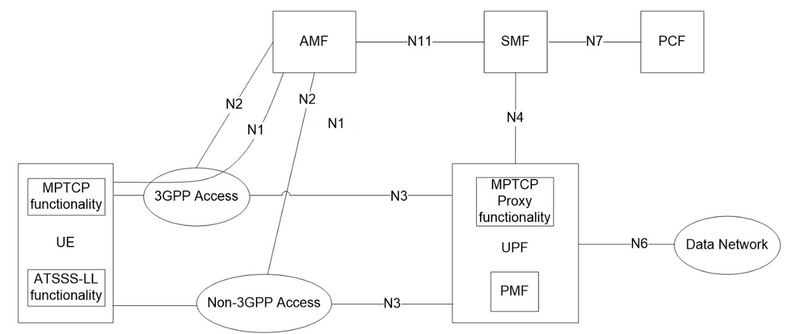
また、同じような発想の話で 5G のコンテキストでは ATSSS(Access Traffic Steering, Switching and Splitting)5と呼ばれる仕組みがあります。
3GPP 環境 (e.g. モバイル通信)と Non-3GPP 環境(e.g. Wi-Fi)の終端装置を UPF に直接入れることで、適切なリンクに合わせて処理を行います。
この話については むねあきさんが書かれた記事 が詳しいのでオススメします。
それにしても PMF みたいなやつは、MPTCP なんで適切なスケジューラーを利用すれば問題ないのではないだろうか?みたいな気持ちがありますが、L3 の知見を L4 にフィードバックしたいということ何でしょうね。確かに L4 のレイヤで言われるより長い時間の統計を取って利用することで嬉しくなったりするかもなーとかは思うので気になるところです。
eBPFとは
eBPF(extended Berkeley Packet Filter) は、Linux カーネル内で実行されるプログラムを実行するための拡張可能な仕組みです。元々はネットワークパケットのフィルタリングに使用されていた Berkeley Packet Filter(BPF)を拡張したもので、現在ではさまざまな用途に広がっています。
eBPF は、プログラムを動的に挿入し、実行できる柔軟な仕組みです。これにより、カーネルの様々な部分で動作する小さなプログラムを実行できます。
struct_opsについて
BPF_STRUCT_OPS と呼ばれる特定のカーネル内関数ポインタを実装する仕組みがあります。これは、 Linux v5.3から入りました。 現在は TCP の輻輳制御(tcp_congestion_ops)を eBPF で記述する為に使われていることが知られています。 例えば Cubic と呼ばれる有名な輻輳制御アルゴリズムは現在は eBPF で記述されており、その例がkernelのリポジトリツリーに含まれています。
このようにカーネルを弄らなくても輻輳制御アルゴリズムの実装をプラグインのように適用できるので、今日ではお手軽にアプリケーションの特性に合わせた通信環境を実装することが可能になりました。
そして、これを応用して今日では MPTCP のスケジューラーが eBPF で書けるようになりました。最初のサポートは Linux v5.19 から入りました(なお完全なサポートや最適化はまだ取り込まれてない)
つまり任意の評価アルゴリズムを書いて任意のサブフローに好きなようにパケットを流し込むといったことが簡単にできるようになったわけですね。
オレオレMPTCPスケジューラーをちょっと作ってみた
ではこのおもしろ技術に触れてみたいと考えるのが今日の本題です。少し触ってみた経験と実装に簡単な解説をつけつつ話して行きます。
今回は Lowest-RTT-First になるバージョンを実装してみました。ここで指す Lowest-RTT-First というのは SRTT が最小の subflow を選択するアルゴリズムとします。また今回は Upstream に入ってない mptcp_net-next の v6.6.0 を対象に説明していきます。
最小構成の例
ひとまず実装物の説明の前に mptcp_net-next という Upstream に入る前のカーネルに置かれている最小構成のスケジューラー実装である mptcp_bpf_first.c を利用して構造と利用法を説明します。
以下が最小構成であるスケジューラーのコードです。これは、ある subflow 1 つに対してのみパケットを投げ続けることができるスケジューラーです。
末尾に書いてある struct mptcp_sched_ops に関数ポインタを登録することで、実際にスケジューラーとして利用できます。
登録が必要なものは次の4つです
- init: スケジューラーをロードした時にコールされる関数
- release: スケジューラーをアンロードした時にコールされる関数
- get_subflow: MPTCP のパケットを投げるのに呼ばれる関数(スケジューラー機能の main 関数部分に当たるようなところ)
- name: sysctl を利用して利用するスケジューラーを決定するのでその時に渡す名前
// SPDX-License-Identifier: GPL-2.0 /* Copyright (c) 2022, SUSE. */ #include <linux/bpf.h> #include "bpf_tcp_helpers.h" char _license[] SEC("license") = "GPL"; SEC("struct_ops/mptcp_sched_first_init") void BPF_PROG(mptcp_sched_first_init, struct mptcp_sock *msk) { } SEC("struct_ops/mptcp_sched_first_release") void BPF_PROG(mptcp_sched_first_release, struct mptcp_sock *msk) { } int BPF_STRUCT_OPS(bpf_first_get_subflow, struct mptcp_sock *msk, struct mptcp_sched_data *data) { mptcp_subflow_set_scheduled(bpf_mptcp_subflow_ctx_by_pos(data, 0), true); return 0; } SEC(".struct_ops") struct mptcp_sched_ops first = { .init = (void *)mptcp_sched_first_init, .release = (void *)mptcp_sched_first_release, .get_subflow = (void *)bpf_first_get_subflow, .name = "bpf_first", };
実際にこれを使う場合はどのようにするかというと、このようにして実行します。
# ebpfのプログラムロード sudo bpftool struct_ops register mptcp_bpf_first.o # sudo bpftool prog list とやると確認ができる # mptcpのスケジューラーのロード sudo sysctl -w net.mptcp.scheduler=bpf_first
これである任意の subflow 1 つのみにパケットを流すような実装ができました。
この仕組みは現在デフォルト機能になってるスケジューラーでも同様に mptcp_sched_ops に詰めてあげています。
該当箇所は この部分 です。
static int mptcp_sched_default_get_subflow(struct mptcp_sock *msk, struct mptcp_sched_data *data) { struct sock *ssk; ssk = data->reinject ? mptcp_subflow_get_retrans(msk) : mptcp_subflow_get_send(msk); if (!ssk) return -EINVAL; mptcp_subflow_set_scheduled(mptcp_subflow_ctx(ssk), true); return 0; }
これは、解説されてると有用なので、ざっくりデフォルトスケジューラーのプログラムの解説をします。
- data->reinject: ここには今投げようとしてるデータが再送されるデータなのかどうかのフラグが含まれています。
- mptcp_subflow_get_retrans: 再送の場合に使われる関数
- アクティブなサブフローの中でTCP 送信待ちのデータがない場合を利用する
- 利用できなければ、backup flag がついているエンドポイントを選ぶ
- mptcp_subflow_get_send: 初めて投げられる時に使われる関数
- linger time(キューがはけるまでの時間)が一番短いsubflowを使います。
sk_wmem_queuedとソケットに書き込むバッファメモリが queue を示しています- このアルゴリズムは blest アルゴリズムを参考にして作られてるらしいです。
- ペーサー(送信データのレートみたいなものです)なども含まれているので、ここが MPTCP の輻輳制御部分もやってそうです。
- 有名なのだと リーキーバケットアルゴリズム とかそういうのが思い出すやつですね。
- linger time(キューがはけるまでの時間)が一番短いsubflowを使います。
細かいことを知りたい場合は ここで呼ばれる mptcp_subflow_get_send 関数 に書いてあるので、MPTCP のスケジューラーを実装したい人は参考になりますので、一度読んでおくと良いです。
Lowest-RTT-First 対応スケジューラー
Smoothed RTT (SRTT)を利用して最小の RTT を見て動く簡単なやつを改造して作ってみました。SRTT というのはローパスフィルタが入った RTT みたいなものです。これの Linux 上での測定アルゴリズムについては このブログ が割とよくまとまっていますので気になる方はどうぞ。
で今回のコードのあるリポジトリは こちら です。これは、mptcp net-next の開発リポジトリに含まれてる mptcp_bpf_burst.c を改造したものです。
ざっくり説明すると、全ての subflow を探索して、利用可能な subflow の中で、なおかつ RTT の最小値を持つ subflow を優先して投げつけるということをしています。これにより RTT が良い subflow を貪欲に選択し続けるみたいな実装が書けました。
(実際には前述したデフォルトのスケジューラーのように、RTTベースだけではなく、ペーシングやqueueの容量などの複合要因を考えるのが良いというのが正解な気もしますが...w)
static int bpf_minrtt_get_send(struct mptcp_sock *msk, struct mptcp_sched_data *data) { struct mptcp_subflow_context *subflow; struct sock *sk = (struct sock *)msk; __u32 selected_minrtt = 0; __u32 selected_subflow_id = 0; __u32 minrtt = 0; struct sock *ssk; int i; for (i = 0; i < data->subflows && i < MPTCP_SUBFLOWS_MAX; i++) { subflow = bpf_mptcp_subflow_ctx_by_pos(data, i); if (!subflow) break; ssk = mptcp_subflow_tcp_sock(subflow); if (!mptcp_subflow_active(subflow)) continue; const struct tcp_sock *tp = bpf_skc_to_tcp_sock(ssk); if (!tp){ continue; } minrtt = tp->srtt_us; if (minrtt < selected_minrtt || (selected_minrtt == 0 && selected_subflow_id == 0)){ selected_minrtt = tp->srtt_us; selected_subflow_id = i; } } mptcp_set_timeout(sk); subflow = bpf_mptcp_subflow_ctx_by_pos(data, selected_subflow_id); if (!subflow){ return -1; } out: mptcp_subflow_set_scheduled(subflow, true); return 0; }
ということで、eBPF を利用して任意のアルゴリズムのスケジューラーを簡単に実装できました。
カーネルのドキュメントを眺めてみると bpf_prog_run に関して BPF_PROG_TYPE_STRUCT_OPS があるので、Unittest とかもしっかり書けそうだなぁというのも嬉しいポイントだと思いました。
引っかかったポイントは、既存実装に含まれていた bpf_tcp_helpers.h の struct tcp_sock のメンバがカーネル本体に含まれる tcp_sock と全然数が違ったことでした。それにより利用できるメンバが制限されていると思って途方に暮れていました。ですが実際に git bleam などで状況確認をしていくと、どうやら構造体の順番や数は関係なく、メンバのフィールド名が勝手に mapping されていたので、普通に利用したいフィールド名を tcp_sock に追加すれば良いとわかりました。この点でしばらくハマってしまっていました。(正直いまだによく分かってない)
それと普段 cilium/ebpf を利用して go で書いて開発してるのですが、その pure go な実装のローダーの上で BPF_PROG_TYPE_STRUCT_OPS が使えず普段使ってるもので動かず悲しい気持ちになりました。maptype はあるんですけどね...誰もやらなかったら試しに改造してパッチを出そうかなと思います。
終わりに
なぜ MPTCP の話をしたのかというと、SFC のとある博士課程の学生と一緒に研究開発をやっていて(thanks @yas-nyan)、その中で MPTCP に関する知見を得たりしたので論文に書かなかったこと含めてちょっと供養をしようと思ったからでした。
僕も博士受けたいと思っていますが、ネタを思いつけず困ってるので迷走してる感じではあります...:innocent:
個人的には次にちゃんと来る技術はマルチパス技術だろうなと思っており、ここ数年で MPTCP 技術の自由度と実装されてる品質が高くなったなと思っています。なので例えばポリシー投入が可能な SDN などの実装で今までにない世界を掘り下げられるのではないかと感じるようになりました。
例えば L3 の知見をもとに L4 を制御するとか、逆に L7 のセマンティクスを L4 にフィードバックするとか。eBPF でスケジューラ実装が書けるので eBPF Map を通じてならアプリケーションとの連携が比較的簡単です。今後こういうのを応用すると、DHCP や BGP 拡張との合わせ技でマルチパススケジューラーのアルゴリズムやトランスポート層の輻輳制御アルゴリズムをサーバーにフェッチさせて、アプリケーションやDCなどのネットワーク特性に合わせてアルゴリズム選択するなど、プロビジョニングの点でも面白いことが出来そうでワクワクしますよね(妄想)
皆さんも eBPF を使っておもしろスケジューラーを書いたりして楽しみましょう:)
参考文献
- Simone Ferlin. BLEST: Blocking estimation-based MPTCP scheduler for heterogeneous networks↩
- Paasch. Experimental Evaluation of Multipath TCP Schedulers, 2014↩
- Florian Aschenbrenner. From Single Lane to Highways: Analyzing the Adoption of Multipath TCP in the Internet, 2021↩
- Oliver Gasser. Clusters in the Expanse: Understanding and Unbiasing IPv6 Hitlists, 2018↩
- 3GPP. TS24.193, 5G System Access Traffic Steering, Switching and Splitting (ATSSS); Stage 3, Release 17↩
- 3GPP. TS23.501, 5G System architecture for the 5G System (5GS), Release 17↩