この記事は BBSakura Networks Advent Calendar 2023 の12/14の記事になります。
まえおき
こんにちは。BBSakura Networksでアルバイトをしている 梅田 です。
私は情報学部の大学1年生です。
私は今までBGPやRoutingに触れてきました。 しかし、今の時代はネットワークだけではなく、ソフトウェアの開発・利用ができることが求められていると感じています。
そのなかで、私が特に興味を持っているソフトウェアによる高速パケット処理に趣味で入門した話について今回書きたいと思います。
モチベーション
私はAS59105 Home NOC Operators' Group (以下HomeNOC)に加入しています。
HomeNOCとは、インターネットに接続する自律システム AS59105を運用している団体です。
活動の詳細はHomeNOC のWebサイトをご覧ください。
(BBSakura NetworksとHomeNOCは関係がなく、個人の趣味の話です。)
今回は、BGPやASの話ではなく拠点間通信に利用しているTunnel接続についてです。
www.homenoc.ad.jp
拠点間のEtherIP接続における問題
HomeNOCでは拠点間の接続にNTTが提供するフレッツ光を利用し、 各拠点間をNEC UNIVERGE IXシリーズ (以下 NEC IX)を利用してEtherIP(RFC3378 ) Protocolで接続しています。
考えられる解決策
HomeNOCでは、EtherIPプロトコルを利用しつつ、特定の問題を解決する必要があります。
問題解決のアプローチとしては以下の3つが挙げられます。
上位機種への交換:
利点: EtherIPに縛られずさまざまな機能が使える
問題: 費用の面で制約がある。
他社製品の検討:
利点: 既存の機器と同等サイズで、NEC IXと違う機能も利用可能です。
問題: 中古市場での流通が少なく、価格が高い。
自作XDP-EtherIP:
利点: 学習になり、カスタマイズと自動化が可能。
問題: メンテナンスコストが発生する。
HomeNOCは非営利で活動しており、高価な機材を複数台購入することは費用の問題があることを踏まえ、汎用的なPCやサーバ上で動作するEtherIPトンネルを開発することを選択しました。
XDPを選んだ背景
さて、高速なソフトウェアによるパケット処理でよく使われるものとしてDPDKやXDPまたKernel Moduleが挙げられます。
今回はタイトルの通りXDPを選びましたが、選定理由としては以下の二つを重視しました。
背景事情として、HomeNOCではデータセンターだけではなく個人の家にも機材をおいて運用しているため設置場所や消費電力の面で制約があることがあげられます。
HomeNOCでは常時大きな通信が流れているわけではないため、DPDKのような基本的にCPUを100%常時使用したパケットの処理では必要以上に多くの電気を使用してしまいます。 昨今の電気代の高騰を考えると消費電力を抑えたいところです。
そこで、XDPを選びました。
XDPはカーネル空間で動作するeBPFで記述可能なパケット処理系です。XDPではネットワークスタックに渡す前のドライバレベルで処理が可能で、また受信処理のリソース最適化はLinuxのNAPIに任せることができるので利用用途にあってると考えました。
成果物
以下のGitHub Repository で公開しています。
github.com
今回実装した機能は以下の二つです。
EtherIP over IPv6: ユースケースとしてフレッツ光のIPv6オプションを利用したVPNである場合が多いため
TCP MSS Clamping: エンドデバイスにMTU/MSSを個別に設定せずにTCP通信を行いたいため
成果物の相互接続性検証
今回は NEC IXと自作 XDP-EtherIPとの相互接続性の検証を行いました。
検証環境の写真
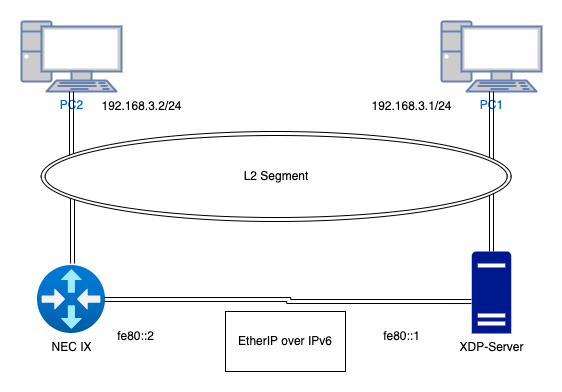
トポロジー
トポロジー図
NEC IXとサーバ間はIPv6 LinkLocalアドレスを利用してEtherIP over IPv6を行っています。
動作方法
NEC IX
NEC IXのTunnelの設定は下記の設定を行っています。
!
interface Tunnel2.0
tunnel mode ether-ip ipv6
tunnel destination fe80::1
tunnel source fe80::2%GigaEthernet2.0
no ip address
bridge-group 1
bridge ip tcp adjust-mss 1404
bridge ipv6 tcp adjust-mss 1384
no shutdown
!
自作XDP-EtherIP
事前に READMEに記述した方法で自作EtherIPゲートウェイをビルドしておきます。
./bin/goxdp --device eth0 --device eth1
検証結果
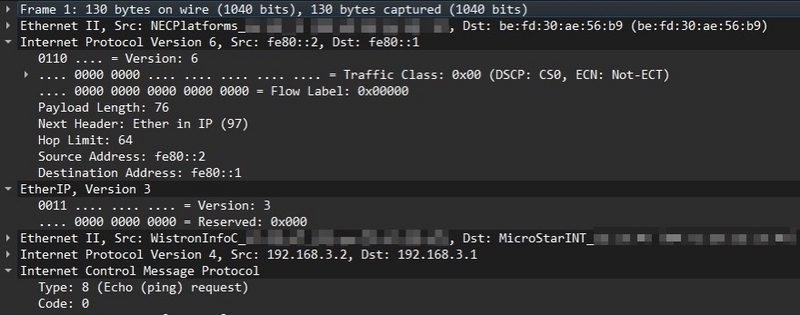
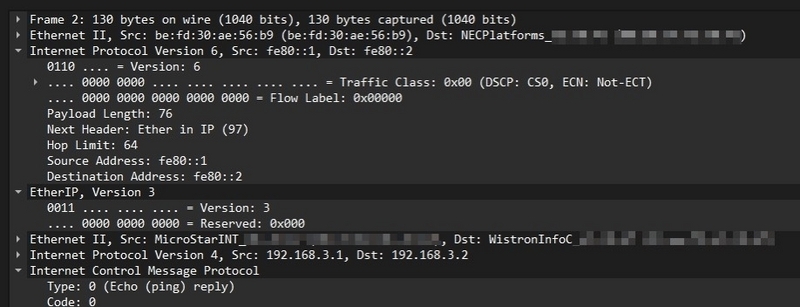
XDP-EtherIPがencapしたEtherIP packetのcapture
Encapsulation TUNNEL:
Tunnel mode is ether-ip ipv6
Tunnel is ready
Destination address is fe80::1
Source address is fe80::2%GigaEthernet2.0
Nexthop address is fe80::1
Outgoing interface is GigaEthernet2.0
Interface MTU is 1500
Path MTU is 1500
Statistics:
27127989 packets input, 38565259003 bytes, 0 errors
6426917 packets output, 4685680696 bytes, 0 errors
Received ICMP messages:
0 errors
NEC IXとの間でEtherIPパケットのやり取りができました。
実装
EtherIPのパケット構造
EtherIPはRFC3378 で標準化されているProtocolで、非常に単純な構造をしています。
+-----------------------+-----------------------------+
| | | |
| IP | EtherIP Header | Encapsulated Ethernet Frame |
| | | |
+-----------------------+-----------------------------+
IP Headerの次のEtherIP Headerは16bitで、中身は固定値になっています。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| | |
| VERSION | RESERVED |
| | |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
実装したEncapのコード
実際のencap処理の流れについて説明します。
input packetの先頭にEthernet Header + IPv6 Header + EtherIP Headerのサイズである56byteの領域を作る
1の各packet headerを作成し作った領域に書き込む
encapをする際のコードを示します。
void *data_end = (void *)(long )ctx->data_end;
void *data = (void *)(long )ctx->data;
struct ethhdr *cpy_ether_header;
struct ethhdr *ether_header;
struct ipv6hdr *ip6_header;
ether_header = data;
if (data + sizeof (*ether_header) > data_end)
{
return XDP_ABORTED;
}
data += sizeof (*ether_header);
uint16_t length = sizeof (ether_header);
struct ethhdr *output_ethernet_header;
struct ipv6hdr *etherip_tunnel_ip6_header;
struct in6_addr etherip_tunnel_ip6_saddr;
struct in6_addr etherip_tunnel_ip6_daddr;
if (bpf_xdp_adjust_head (ctx, 0 - (int )sizeof (struct ethhdr) - (int )sizeof (struct ipv6hdr) - (int )sizeof (struct etherip_hdr)))
{
return XDP_ABORTED;
}
data = (void *)(long )ctx->data;
data_end = (void *)(long )ctx->data_end;
if (data + sizeof (struct ethhdr) > data_end)
{
return XDP_ABORTED;
}
output_ethernet_header = data;
uint8_t dmac[6 ] = {0x00 , 0x60 , 0xb9 , 0xe6 , 0x20 , 0xfb };
uint8_t smac[6 ] = {0xbe , 0xfd , 0x30 , 0xae , 0x56 , 0xb9 };
output_ethernet_header->h_proto = htons (ETH_P_IPV6);
__builtin_memcpy (output_ethernet_header->h_dest, dmac, sizeof (dmac));
__builtin_memcpy (output_ethernet_header->h_source, smac, sizeof (smac));
data += sizeof (struct ethhdr);
if (data + sizeof (struct ipv6hdr) > data_end)
{
return XDP_ABORTED;
}
etherip_tunnel_ip6_header = data;
etherip_tunnel_ip6_header->version = 6 ;
etherip_tunnel_ip6_header->priority = 0 ;
etherip_tunnel_ip6_header->nexthdr = 97 ;
etherip_tunnel_ip6_header->hop_limit = 64 ;
uint8_t saddr[16 ] = {0xfe , 0x80 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 ,
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x01 };
__builtin_memcpy (etherip_tunnel_ip6_saddr.s6_addr, saddr, sizeof (saddr));
etherip_tunnel_ip6_header->saddr = etherip_tunnel_ip6_saddr;
uint8_t daddr[16 ] = {0xfe , 0x80 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 ,
0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x02 };
__builtin_memcpy (etherip_tunnel_ip6_daddr.s6_addr, daddr, sizeof (daddr));
etherip_tunnel_ip6_header->daddr = etherip_tunnel_ip6_daddr;
data += sizeof (struct ipv6hdr);
struct etherip_hdr *etherip_header;
etherip_header = data;
if (data + sizeof (struct etherip_hdr) > data_end)
{
return XDP_ABORTED;
}
etherip_header->etherip_ver = 0x30 ;
etherip_header->etherip_pad = 0x00 ;
etherip_tunnel_ip6_header->payload_len = htons (data_end - data);
data += sizeof (struct etherip_hdr);
struct ethhdr *old_ether_header;
old_ether_header = data;
if (data + sizeof (struct ethhdr) > data_end)
{
return XDP_ABORTED;
}
...
また、TCP MSSを調整する場合には上に加えて下記の処理を行います。
元のinput packetのpacket Headerを順番に読む。
IP Headerの次のパケットがTCPでSYN flagが立っている場合、元のTCPのoption fieldのMSSの値を読む。
読み取った元の値が設定したいMSS値より大きい場合のみ、MSSの値を更新する。
TCPのchecksumの更新。
if (old_ether_header->h_proto == htons (ETH_P_IP)) {
data += sizeof (struct ethhdr);
struct iphdr *old_ip_header;
old_ip_header = data;
if (data + sizeof (struct iphdr) > data_end) {
return XDP_ABORTED;
}
if (old_ip_header->protocol == 6 ) {
data += sizeof (struct iphdr);
struct tcphdr *old_tcp_header;
old_tcp_header = data;
if (data + sizeof (struct tcphdr) > data_end) {
return XDP_ABORTED;
}
if (old_tcp_header->syn == 1 ) {
data += sizeof (struct tcphdr);
struct tcpopt *old_tcp_options;
old_tcp_options = data;
if (data + sizeof (struct tcpopt) > data_end) {
return XDP_ABORTED;
}
if (old_tcp_options->kind == 2 && old_tcp_options->len == 4 ) {
data += sizeof (struct tcpopt);
uint16_t *old_mss;
old_mss = data;
if (data + sizeof (uint16_t ) > data_end) {
return XDP_ABORTED;
}
uint16_t old_mss_value = *old_mss;
if (ntohs (*old_mss) > 1404 ) {
uint16_t new_mss = htons (1404 );
__builtin_memcpy (old_mss, &new_mss, sizeof (uint16_t ));
update_checksum (&old_tcp_header->check, old_mss_value,
htons (1404 ));
}
}
}
}
}
実装したDecapのコード
decapはencapと異なり、encapしたときに先頭につけた56byteをカットするだけの処理です。
IPv6 packetである
IPv6 packetのNextHeaderがEtherIP(97)である
先頭56 Byteをカット
処理したパケットを別のinterfaceに送出
void *data_end = (void *)(long )ctx->data_end;
void *data = (void *)(long )ctx->data;
struct ethhdr *ether_header;
struct ipv6hdr *ip6_header;
ether_header = data;
if (data + sizeof (*ether_header) > data_end)
{
return XDP_ABORTED;
}
uint16_t h_proto = ether_header->h_proto;
if (h_proto == htons (ETH_P_IPV6))
{
data += sizeof (*ether_header);
ip6_header = data;
if (data + sizeof (*ip6_header) + 2 > data_end)
{
return XDP_ABORTED;
}
if (ip6_header->nexthdr == 97 )
{
data += sizeof (*ip6_header) + 2 ;
if (data + sizeof (*ip6_header) + 2 > data_end)
{
return XDP_ABORTED;
}
struct ethhdr *etherip_ether_header;
etherip_ether_header = data;
bpf_xdp_adjust_head (ctx, sizeof (*ether_header) + sizeof (*ip6_header) + 2 );
bpf_redirect (3 , 0 );
return XDP_REDIRECT;
}
}
実装過程で苦労した点
decapは簡単ですが、encapではいくつか苦労しました。
IPv6 Payload Lengthの設定ミス
encapするときは先頭にパケットヘッダーを新たに追加しますが、パケットの後方のことも考えなければなりません。
etherip_tunnel_ip6_header->payload_len = htons(data_end - data);
この値が本来のサイズより小さい値が設定されている場合、Wiresharkやtcpdumpで見たときにpayload lengthを超えたバイト列は破棄されてしまい見ることができません。
テストコードの追加
今回のプログラムには処理されたパケットが正しく動いているか確認するためのテストコード を書いています。
https://github.com/x86taka/xdp-etherip/blob/dev/pkg/coreelf/xdp_test.go
テストでは、gopacket を利用してTCPのSYNパケット作成しXDPのプログラムがEtherIPパケットにencapしたものと想定される正しいencap後のパケットと比較しチェックしています。
github.com
このテストを行うことで、TCP MSSの書き換えとTCP checksumが正しいかについても検証ができました。
XDPに処理させるpacketの生成
opts := gopacket.SerializeOptions{FixLengths: true , ComputeChecksums: true }
iph := &layers.IPv4{
Version: 4 , Protocol: layers.IPProtocolTCP, Flags: layers.IPv4DontFragment, TTL: 64 , IHL: 5 , Id: 1160 ,
SrcIP: net.IP{192 , 168 , 100 , 200 }, DstIP: net.IP{192 , 168 , 30 , 1 },
}
tcph := &layers.TCP{
Seq: 0x00000000 ,
SYN: true ,
Ack: 0x00000000 ,
SrcPort: 1234 ,
DstPort: 80 ,
Options: []layers.TCPOption{
{
OptionType: 0x02 ,
OptionLength: 4 ,
OptionData: []byte {0x05 , 0xb4 },
},
{
OptionType: 0x04 ,
OptionLength: 2 ,
},
{
OptionType: 0x08 ,
OptionLength: 10 ,
OptionData: []byte {0x00 , 0x00 , 0x00 , 0x00 , 0x00 },
},
{
OptionType: 0x01 ,
OptionLength: 1 ,
},
{
OptionType: 0x01 ,
OptionLength: 1 ,
},
},
}
tcph.SetNetworkLayerForChecksum(iph)
buf := gopacket.NewSerializeBuffer()
err := gopacket.SerializeLayers(buf, opts,
&layers.Ethernet{DstMAC: []byte {0x00 , 0x00 , 0x5e , 0x00 , 0x11 , 0x01 }, SrcMAC: []byte {0x00 , 0x00 , 0x5e , 0x00 , 0x11 , 0x02 }, EthernetType: layers.EthernetTypeIPv4},
iph,
tcph,
gopacket.Payload(payload),
)
XDPが処理して期待されるパケットの生成
ip6h := &layers.IPv6{
Version: 6 ,
NextHeader: layers.IPProtocolEtherIP,
HopLimit: 64 ,
SrcIP: net.ParseIP("fe80::1" ),
DstIP: net.ParseIP("fe80::2" ),
}
eiph := &layers.EtherIP{
Version: 3 ,
Reserved: 0 ,
}
iph := &layers.IPv4{
Version: 4 , Protocol: layers.IPProtocolTCP, Flags: layers.IPv4DontFragment, TTL: 64 , IHL: 5 , Id: 1160 ,
SrcIP: net.IP{192 , 168 , 100 , 200 }, DstIP: net.IP{192 , 168 , 30 , 1 },
}
tcph := &layers.TCP{
Seq: 0x00000000 ,
SYN: true ,
Ack: 0x00000000 ,
SrcPort: 1234 ,
DstPort: 80 ,
Options: []layers.TCPOption{
{
OptionType: 0x02 ,
OptionLength: 4 ,
OptionData: []byte {0x05 , 0x7c },
},
{
OptionType: 0x04 ,
OptionLength: 2 ,
},
{
OptionType: 0x08 ,
OptionLength: 10 ,
OptionData: []byte {0x00 , 0x00 , 0x00 , 0x00 , 0x00 },
},
{
OptionType: 0x01 ,
OptionLength: 1 ,
},
{
OptionType: 0x01 ,
OptionLength: 1 ,
},
},
}
tcph.SetNetworkLayerForChecksum(iph)
err := gopacket.SerializeLayers(buf, opts,
&layers.Ethernet{DstMAC: []byte {0x00 , 0x60 , 0xb9 , 0xe6 , 0x20 , 0xfb }, SrcMAC: []byte {0xbe , 0xfd , 0x30 , 0xae , 0x56 , 0xb9 }, EthernetType: layers.EthernetTypeIPv6},
ip6h, eiph,
&layers.Ethernet{DstMAC: []byte {0x00 , 0x00 , 0x5e , 0x00 , 0x11 , 0x01 }, SrcMAC: []byte {0x00 , 0x00 , 0x5e , 0x00 , 0x11 , 0x02 }, EthernetType: layers.EthernetTypeIPv4},
iph,
tcph,
gopacket.Payload(payload),
)
また、テストコードを実装する上でgopacketのEtherIPに関するコードにSerializeTo関数が不足していたため、実装を行いました。
github.com
まとめ
プログラミングにおいては、Hello World程度のC言語習得レベルで開発をスタートし、自力でEtherIPのencap/decapやTCP MSS Clampingまで実装したことは大きな学びになりました。
今後の課題
Multi Coreに対応させたい
EtherIPのパケットは、5tupleのhashがTunnel終端で固定になってしまうためNICのRSSが効かず1 coreでしか処理ができません。
eBPF Mapsによる、動的なTunnelの作成
現状の実装では、macアドレスやTunnnel終端の宛先アドレスや送信元アドレスがハードコードされています。
高速化の工夫
今の実装では、XDP_REDIRECTを行って別のinterfaceからパケットを送出しています。
謝辞
今回の記事を書くにあたって、BBSakura Networksの早坂さんにアドバイスをいただき、テストコードの実装などを行うことができました。
また、最初に実装したコードについても公開しています。
github.com
次回の記事もお楽しみに!