目次
- 目次
- はじめに
- Internetトラフィックとフロー分析
- pmacctでできること
- nfacctdによる分散処理構成例
- 1段目:サーバー間分岐転送用tee server
- 2段目:分析処理サーバーでのサーバー内NetFlow分岐
- まとめ
はじめに
こんにちは。BBSakura Networksの矢萩です。
この記事は BBSakura Networks Advent Calendar 2024 4 日目の記事」になります。
BBSakura Networksでは、親会社BBIXが手掛けているIX=Internet eXchange向けのユーザシステムの開発も行っています。BBIXではユーザポータルでのインタフェーストラフィック以外に、別サービスとしてNetFlowデータによるユーザトラフィックの詳細分析サービスを提供しています。 今回は、このシステムで使っているNetFlowデータを分岐転送させてサービス提供と開発を共存する方法を紹介したいと思います。
Internetトラフィックとフロー分析
フロー分析システムは、ネットワーク運用効率化のヒントを提供するシステムです。 IXユーザの課題となっている以下の情報を見える化します。
- どこのネットワークのトラフィックが多いか?
- トラフィックの多いネットワークはどの経路(Transit/IX)を主に使っているのか?
Internetはネットワーク(Asyncronous System=AS)同士が相互接続することで全世界を包括するコンピュータネットワークを構成しています。IXにはASが集まり、それぞれが相互接続(Peering)することで、Internetでのトラフィック交換を効率的に行います。 ネットワーク接続の方法は
- (1) 相互接続:IXやPNI 相互接続 コスト安価
- (2) トランジット接続:Transit 上流接続 コスト高価
があり、(2)上流接続部分を(1)相互接続への比重を上げていくことことで、ネットワーク運用費用のコスト効率化することができます。私が担当しているフロー分析システムはNetFlowデータに含まれるAS番号情報から以下の詳細トラフィック分析結果を提供しています。
- 全体トラフィック分析(①AS全体、②トランジット経由、③IX経由、④PNI経由)
- ASごとの通信インタフェース分析
- インターフェース単位でのAS分析
これらの情報から、効率的なトラフィック交換を実現するためのルーティングポリシーを作っていくヒントを得ることができます。
◾️トランジット経由での分析の例
全体トラフィック分析:トランジット経由の例です。この場合、トランジットで一番多い通信はAS13335 とわかります。それではAS13335はどのインターフェースを使って通信しているのでしょうか。こちらはAS13335のOrigin AS分析でわかります。

◾️Origin AS分析の例
Origin AS分析では、AS13335をOriginとする通信がどのインタフェース経由で通信しているかを分析します。戻りトラフィックは ASBdr3_TO_IX1 ASBdr3_TO_IX2 ASBdr3_TO_Uplink3を使っており、 一番多いのはトランジットである ASBdr3_TO_Uplink3 になっています。このトラフィックをIX経由や直接Peer接続にすることができればネットワークのコスト効率を上げることができ、中継区間も減るので遅延改善も期待できます。フロー分析することでこのようなネットワーク品質向上のヒントが得られるわけです。

NetFlowでのトラフィック計測とは
NetFlowは、Ciscoが開発した統計手法を用いたトラフィック情報計測プロトコルです。UDPの上で実装されています。 ルーターやスイッチなどのネットワーク機器に実装されており、ネットワーク機器を経由する通信を一つのネットワークフローとして捉え、各通信フローをサンプリング取得することで、通信の中身を分析することができます。 NetFlowデータには以下のレコードが記録されています。
- 発信元IP(SrcAS)・送信先IP(DstAS)
- 発信元MAC・送信先MAC
- 発信元AS・送信先AS
- 通信フローの存在期間
- 通信フローの通信量
- 利用プロトコル(TCP/UDP/...)
- 利用ポート
- その他
大量のNetFlowデータを統計解析することで、SNMPインタフェーストラフィック計測ではわからなかった、あるOrign ASのトラフィックがどのインタフェースを経由して通信しているのかといった詳細分析を可能とします。
商用サービス化の課題:NetFlowの複製・分岐
フロー分析サービスは、BBIXユーザ向けのオプションサービスとして提供しています。商用サービスとして提供するためには、データ欠落を発生させない商用品質の確保が必須であり、開発当初、以下の機能実装が課題となっていました。
- バックアップサーバーのためのNetFlowコピー
- いろいろな分析用途プロセスにNetFlowコピー
- 負荷分散のためのNetFlowデータ分岐
NetFlowの分岐・転送可能にすることで、以下のメリットが受けられることが予想されていたためです。
- オンラインサーバーと全く同じデータで開発ができるため、サービスに影響なしで開発が可能
- オンラインサーバーと全く同じデータで開発ができるため、オンラインコードとの結果比較が容易になり、開発効率があがる
- バックアップサーバー・プロセスへの分岐が可能となり、複雑なフロー解析処理でのデータ欠落を防止できる
- ユーザ単位でのNetFlow振り分け転送機能により、オンラインサーバーのユーザ収容分散が可能となる
これを解決してくれたのがpaolo lucenteさん作の pmacct です。
 出展:pmacct project
www.pmacct.net
出展:pmacct project
www.pmacct.net
pmacctでできること
pmacctは以下の機能を実現できます。
- NetFlow(v5,v8,v9,IPFIX)/sFlow(v2,v4,v5)/pcap/NFLOGを収集し、
- いろんなフォーマットに保存(csv/text/RDBMS/noSQL/kafka/RabbitMQ/...)
- 一つの入力データを複数に分岐・転送可能
pmacctは取り扱う入力データごとに異なるdaemonが準備されており、今回はNetFlow用のnfacctdで分岐処理・コピー処理を行います。
- nfacctd (NetFlow Accouting deamon)
- sfacctd (sFlow Accouting daemon)
- pmacctd (packet capture base accouting daemon)
nfacctdはデフォルトでCSVなどのtext出力のほか分岐転送(tee)処理は標準機能として実装しているので、extentionの追加なしで使えます。
nfacctdによる分散処理構成例
フロー分析システムを構築にあたり、ルーターから直接NetFlowデータを受信して、処理サーバーに分配する1段目と、実際の分析処理を行う2段目の多段構成で組むこととしました。
- 1段目 Server1:NetFlow teeサーバー
- 2段目 Server2:online分析サーバー
- 2段目 Server3:開発分析サーバー

1段目:サーバー間分岐転送用tee server
サーバー内の複数プロセスに同じNetFlowデータを分配するには、loopbackアドレスに各プロセス用のUDPポートを設定することで、プロセスへの分配転送が可能になります。

サーバー間分岐転送用tee server設定
設定を行うのはnfacctd用の設定と転送先設定になります。 nfacctdサーバー間転送設定は以下のように行います。ここでの肝はtee_receiversに設定される転送先設定になります。
server1:/etc/pmacct$ cat nfacctd_tee_server1.conf daemonize: false debug: false logfile: /var/log/pmacct/nfacctd_tee_server1.log pidfile: /var/pmacct/pid/nfacctd_tee_server1.pid nfacctd_ip: 10.0.1.20 nfacctd_port: 20001 plugins: tee[server1] tee_receivers[server1]: /etc/pmacct/tee_server.lst tee_transparent: true plugin_pipe_size: 204800 ! end of file server1:/etc/pmacct$
サーバー間分岐転送用転送先設定
転送先設定は以下のように行います。 転送先については、Copyしたい数だけidを増やしていき、転送先のIPとポートを追加することで分岐先を増やすことが可能です。
server1:/etc/pmacct$ cat tee_server.lst id=1 ip=172.16.1.100:20001 id=2 ip=172.16.1.200:20001 server1:/etc/pmacct$
サーバー間分岐転送 tee process起動
設定が完了したら、以下のように -D のdaemon指定で起動するとことで、NetFlowのサーバー分岐転送が開始します。
$ sudo pmacct -D -f /etc/pmacct/nfacctd_tee_server1.conf
2段目:分析処理サーバーでのサーバー内NetFlow分岐
ルータから受信したNetFlowは前章の手順で、オンラインサーバーと開発サーバーに分配されました。サーバー内においても、用途別にプロセスを分散して同じNetflowデータにて並列処理を行うことで開発効率があがります。
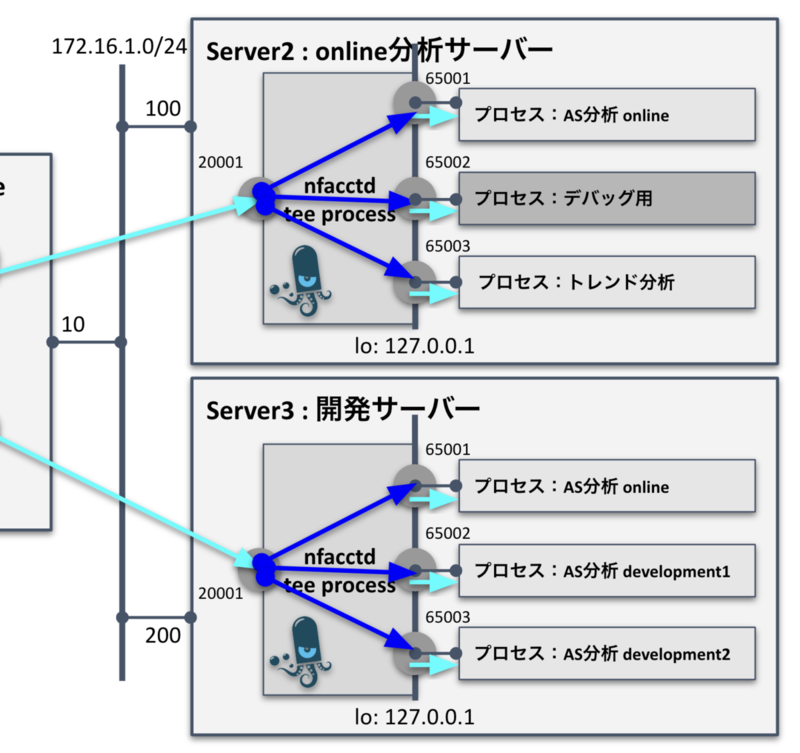
例えば、
- AS分析プロセス
- トレンド分析プロセス
- デバッグプロセス用予備
という感じで、異なる観点での分析プロセスに分配するといった用途分岐です。 また、開発サーバーにおいては、
- AS分析プロセス:オンライン main branch
- AS分析プロセス:開発 development1 branch
- AS分析プロセス:開発 development2 branch
を並行稼働させて、ブランチ毎にロジックを変えて比較しながら開発できれば、正解(main branch)を見ながら開発ブランチごとの結果比較を行うことが可能となります。
サーバー内分岐転送用tee server設定
内部プロセス転送設定は以下のようになります。 設定を行うのはnfacctd用の設定と転送先設定になります。
Server2 online用tee設定
server2:/etc/pmacct$ cat nfacctd_tee_server.conf daemonize: false debug: false logfile: /var/log/pmacct/nfacctd_tee_server.log pidfile: /var/pmacct/pid/nfacctd_tee_server.pid nfacctd_ip: 172.16.1.100 nfacctd_port: 20001 plugins: tee[server] tee_receivers[server]: /etc/pmacct/tee_server.lst tee_transparent: true plugin_pipe_size: 204800 server2:/etc/pmacct$
Server2/Server3 online用 サーバー内プロセス転送先設定
サーバー内の複数プロセスに同じNetFlowデータを分配するには、loopbackアドレスに各プロセス用のUDPポートを設定することで、プロセスへの分配転送が可能になります。
◾️サーバー構成例
- プロセス1用UDPポート: 127.0.0.1 :65001
- プロセス2用UDPポート: 127.0.0.1 :65002
- プロセス3用UDPポート: 127.0.0.1 :65003
このように複数のUDPポートに分岐転送設定しておくことで、必要なプロセスを開いているUDPポート指定で起動させれば同じNetFlowデータをもとに異なる用途のプロセスを並行して駆動することが可能となります。 内部プロセス用転送先設定は以下のように行います。転送先については、Copyしたい数だけidを増やしていき、転送先UDPポートを追加することで分岐先を増やすことが可能です。今回の例ではServer2/Server3ともに同じポートに転送することなっているので、共通になります。
server2:/etc/pmacct$ cat tee_server.lst id=1 ip=127.0.0.1:65001 id=2 ip=127.0.0.1:65002 id=3 ip=127.0.0.1:65003 server2:/etc/pmacct$
Server3 開発サーバー用tee設定
こちらはServer2アドレスとServer3アドレスが変わっている以外は同じ設定になっています。
server3:/etc/pmacct$ cat nfacctd_tee_server.conf daemonize: false debug: false logfile: /var/log/pmacct/nfacctd_tee_server.log pidfile: /var/pmacct/pid/nfacctd_tee_server.pid nfacctd_ip: 172.16.1.200 nfacctd_port: 20001 plugins: tee[server] tee_receivers[server]: /etc/pmacct/tee_server.lst tee_transparent: true plugin_pipe_size: 204800 server3:/etc/pmacct$
サーバー内分岐転送 tee process起動
設定が完了したら、以下のように -D のdaemon指定で起動するとことで、NetFlowのサーバー内分岐転送が開始します。
$ sudo pmacct -D -f /etc/pmacct/nfacctd_tee_server1.conf
あとは必要な分析プロセスを開いているUDPポートにbindして立ち上げてあげることで、同じNetFlowデータでの並列処理を行うことができます。
まとめ
AS運用を深掘りしていくと、NetFlow/sFlowによる通信フロー分析が必須になってきます。AS/IX運用に携わった経験から自分が欲しいフロー分析サービスを独自開発してきたのですが、商用品質で安定提供していく上では、NetFlowオリジナルデータの分岐転送が大きな課題となっていました。紹介させていただいた方式は安定稼働実績が確認されている手法ですので、参考にしていただければ幸いです。
今回はNetFlowデータをリアルタイム並列駆動する方法でしたが、NetFlowデータをMessage Queueに保存して非リアルタイムに処理する手法もあります。リクエストがあれば紹介していきたいと思います。