この記事は BBSakura Networks Advent Calendar 2024 の 12/14(土)の記事です。
こんにちは BBSakura Networks 3年目の金井 (@masu-mi.bsky.social , @masu-mi ) です。
ここ数年 eBPF は注目され続けてますね。先日 BBSakura Networks もスポンサーとして eBPF Japan Meetup #2 に携わりました。
これについては、16日の記事として松下さんが参加報告をしてくれたようです 。
そこで eBPF の個人的なおもしろトピックを紹介したいと思います。
はじめに断っておきますが、概念実証など本番利用からすこし離れたトピックが中心で、最新の話題でもありません。
タイトルがキャッチーな感じの発表でした。
スライドの前半で Tigger: A Database Proxy That Bounces with User-Bypass (VLDB'23) が Statless Systems として紹介されています。
後半の BPF-DB が Stateful System のようです。しかし発表以外で公開された情報を見つけられず詳細はつかめませんでした。
Tiger(Stateless Systems) の説明
内容は PostgreSQL 用コネクションプールを eBPF でユーザースペースバイパスして高速化したというものです。プロジェクトページは User-bypass Methods です。
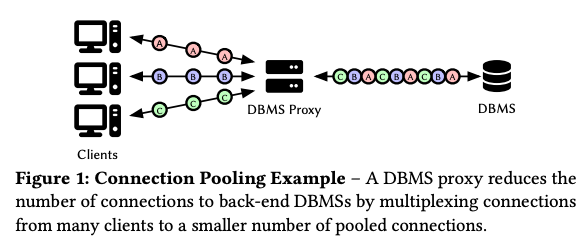
下の図のようなコネクションプール機能を持ったプロキシの性能改善に eBPF を使っています。
Tiger: DBMS Proxy 概要
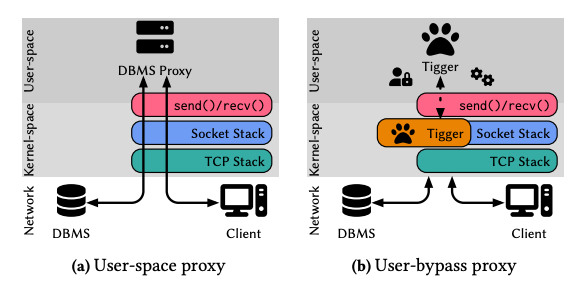
メッセージ交換機能を eBPF プログラムとして主に Socket Stack に挟んでいるようです。
本文中では eBPF プログラムを ソケット, TC レイヤにアタッチするという記述はありましたが具体的なプログラムタイプは確認できませんでした。
また実装では stack, array, sockmap といった eBPF Maps を使っているようです。
Tiger: アーキテクチャ(User-bypass proxy)
ref. Tigger: A Database Proxy That Bounces with User-Bypass (VLDB'23)
Tiger は、セッション確立をユーザースペースで行うようです。そしてセッション確立後のメッセージ転送は fast path として eBPF プログラムで取り扱うという流れです。
3.1 Kernel-Bypass vs. Uesr-Bypass のなかで両者のアプローチの利点や利用される技術やライブラリが紹介されてます。
4.1 章で具体的に sockmap を使ってプロキシ実現するやり方を書いていて、5.章で Tigger のアプリケーションレベルの組み込みを説明しています。
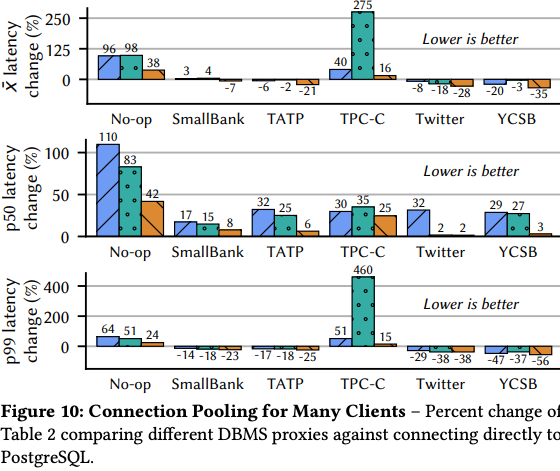
性能試験では PgBouncer や Odyssey とレイテンシーを比較しています。
評価項目は、クライアントと DBMS の直接接続を基準に、プロキシ構成でのレイテンシー悪化率でした
環境は AWS 上で複数のインスタンスで実行していました
ワークロードは、 TATP , TPC-C , YCSB といった代表的なワークロードで行っていた
TATP というテレコム向けのベンチマークも含んでいるのは面白いですね。
試験環境をちゃんと評価しないと意味がないのでグラフだけ載せても仕方ないのですが派手なので載せておきます。 ここで Nop-op は空クエリを投げる試験のようです。
詳細は論文を読んでください。
Tiger: 性能比較 (グラフ部分抜粋)
ref. Tigger: A Database Proxy That Bounces with User-Bypass (VLDB'23)
BPF-DB(Stateful Systems) の説明
Tail Call で構成された eBPF マップを利用して eBPF プログラムのための Key-Value Store を作った話みたいです。
使える命令は BEGIN, SET, GET, COMMIT の4つです。
eBPF Maps はテーブル用途にインデックス用1つとサイズ別のバリュー用3つの計4つで構成しているようです。WAL ログや TXS など他の Maps の存在も示唆されてますが詳細は明かされてません。
インデックス更新はMVCC with strict 2PC(NO WAIT) という方式を採用しているとスライドにはありました。
2PL(NOWAIT)
レコードごとにロックを取得していき部分的な解放を行わない
ロック取得失敗時は ABORT
インデックステーブルでキーに対して、ロック情報・複数バージョンの値への参照とタイムスタンプを保持
SET で不要なバージョンの破棄
説明に An empirical evaluation of in-memory multi-version concurrency control (VLDB '2017) のリンクが表示されていたのでこちらを採用していそうです。
永続性のためにリングバッファでユーザースペースに WAL ログを送っているようです。ユーザースペース側でコンパクションを行い delta checkpoint を作成するとありました。
Flink の Checkpointing みたいなことをやってそうだなと感じましたが詳細が明かされてないので何とも言えません。
感想
Tiger の論文 では 3.1 Kernel-Bypass vs. Uesr-Bypass のなかで User-Bypass のメリットとして L1-L4 をカーネルに任せられことが挙げられており、 kTLS のおかげで User-Bypass を選べるようになったと説明してました。
ここで参考文献となったセッション と Cilium の資料いくつか読むとよさそうです。
また、最近のカーネルのネットワークスタックも改善しているといくつかリファレンスが紹介されていたので読みたいなと思いました。
Diameter Relay Agent (DRA) など L4 を終端する中継機はいろいろあるので適用先は探せそうです。
複雑な初期化処理をユーザースペースに任せて性能が要求される単純な部分をカーネルに任せるのは定番のパターンなので構成自体は目新しく感じなかった覚えがあります。
BPF-DB はほとんど詳細が公開されてないので何とも言えません。
特に永続化の部分と SET, COMMIT の Tail Call フローの説明がないので困ります。
Dragonfly との性能比較も評価するためにも早く詳細が公開されないかなと思いました。
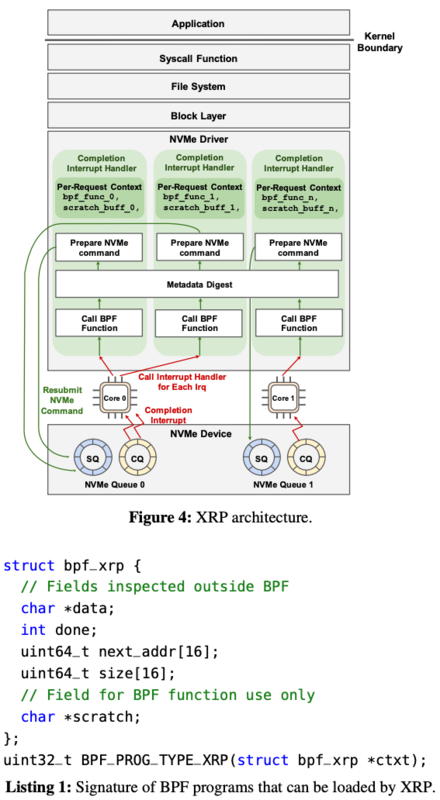
Linux カーネルを拡張して XRP という eBPF プログラムのフレームワークを作成しています。
XRP では eBPF を NVMe driver で動かし FS, BIO をバイパスすることで lookup, aggregation を高速化したようです。
ざっくりした説明
背景など
背景として NVM Express Revision 2.0(NVMe2.0) はハードウェアレイヤが十分に高速でソフトウェアのオーバーヘッドが無視できなくなっているということが挙げられてます。
この論文や同じチームの BPF for storage: an exokernel-inspired approach (HotOS'21) のなかで
NVM Express Revision 2.0(NVMe2.0) で下のようなグラフが出てきます。
HW 性能進歩による SW オーバーヘッドの割合増加
ref. XRP: In-Kernel Storage Functions with eBPF (OSDI ‘22)
これは Optana P5800X で O_DIRECT を使って 512B のランダムリードで試験していて、レイテンシーへのオーバーヘッドでソフトウェアおける割合が 50% 近くまで来てます。
これに対して eBPF を使いとカーネル内で I/O request resubmission(再提出)することで折り返すことでカーネル処理を減らそうというのが主旨です。
設計など
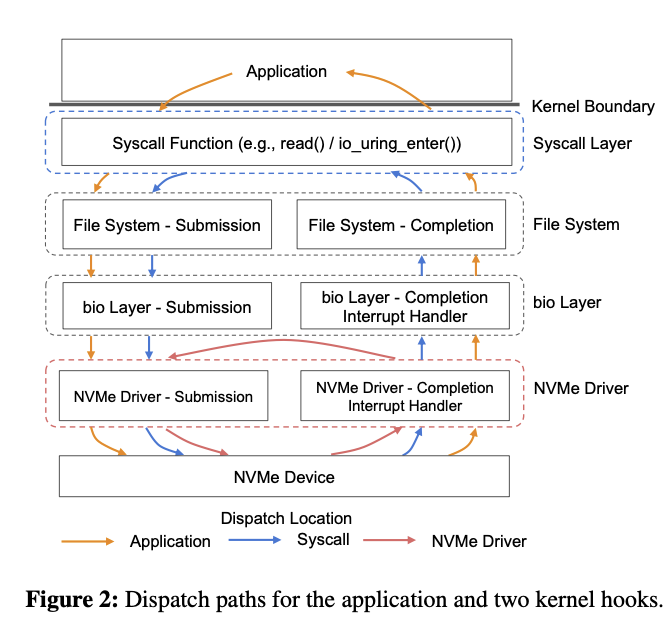
syscall レベルと NVMe driver レベルと2つのアプローチで比較しています。
XRP アーキテクチャ (syscall vs driver)
ref. XRP: In-Kernel Storage Functions with eBPF (OSDI ‘22)
この性能評価では深さ10の B+木 の lookup 試験を行っているようです。NVMe driver レベルで実施したバイパス処理で IOPS の改善で約 2.5倍と書かれていました。
また論文のなかではレガシーな read と io_uring での比較も行っていてどちらでも改善がみられたようです。
具体的な値はワークロードで大きく変わりそうなのだけど効果は大きそうに思いました。
XRP は NVMe 割り込みハンドラで I/O request resumptions を行う仕組みで、3つの技術要素で構成されてるようです。
BPF hook
ファイルシステムの変換
新しい物理オフセットで次の NVMe I/O request の 再提出(resumption)
XRP デザイン
ref. XRP: In-Kernel Storage Functions with eBPF (OSDI ‘22)
XRP の設計方針は 4つあげられています
One file at a time.
XRP で chain される(連続実行される) I/O request resumptions は 1ファイル内に限定する。
Stable data structures.
ファイルレイアウトとその配置(pointer) は長期間変化しないファイルを対象とする。
User-managed caches.
ファイルシステムのページキャッシュに安全にアクセスできないため、XRP を利用する DBMS はユーザースペースでキャッシュしてることを前提とする。
Slow path fallback.
(ファイルサイズが変更されたなど)何らかの理由で XRP によるファイル内 travesal が失敗した時には、 DBMS はユーザースペースに fallback して対応する。
これらは、次のような設計課題と観察事実を踏まえた設計判断のようです。
設計課題には NVMe Driver で実行するとファイルシステムやセキュリティの情報が欠落してしまうことと、並行処理によるファイルの利用範囲が処理中に変更されてしまうことの2つが挙げられています。
また観測事実として、多くのデータベースではストレージ上のレコードやファイルサイズが長い間変化しないことが書かれていました。
このプロジェクトありがたいのはカーネルにパッチ当てたソースコードを公開しているところ。
XRP というリポジトリが XRP プロジェクトの中核で改変した Linux カーネルや BPF-KV という参考実装を含むほか、XRP 対応版の WiredTiger や試験用のYCSB まで含んでいました。
将来の目標が2つ挙げられています。
まず、 smart storage device や FPGA を用いたハードウェアオフロードです。
NVMe Computational Storage に関係した動きのようです。
もう一つは、 networked storage です。
こちらも翌年にプレプリント BPF-oF: Storage Function Pushdown Over the Network が公開されています。
この実装では NVMe-oF (NVMe over Fabric) で Pushdown を行ったようです。
プレプリントを読むと NVMe Driver が I/O 命令を BIO サブシステムに投げたりしていて面白いです。
XRP + BPF-oF 対応版 RocksDB のソースコードも公開されていました。
感想
Linux を拡張した試験実装を読めば eBPF の用途を広げるやりかたが学べそうなので興味をもっています。
XRP 実装のために行った Linux カーネルの変更は 900 行以下みたいです。
また、一部の処理を低レイヤに押し付けて最適化する場面にはしばしば出会います。 DBMS という複雑な具体例で制限された汎用性を意識したフレームワークを設計しているというのは学ぶ価値があるなと思いました。
次は eBPF ISA が RFC で標準化されている話です。これ自体はなんか標準化されるのかくらいで気に留めてませんでした。
上述の XRP を調べていた時に関連記事 Standardizing BPF [LWT.net] を見つけたため面白かったので紹介します。
どうやら、もともとの「BPF のプラットフォーム独立」の意味は異なるアーキテクチャの Linux でも動く程度だったが状況が変わったという趣旨で標準化についての相談してました。
背景に挙げられていた項目は Windows での eBPF サポート、 ネットワーク機器での XDP のオフロード、そして XRP という試みの行き詰まり、でした。
この記事では NVMe Computational Storage というコンセプトはあっても、 NVMe ベンダーは BPF 標準化されないと大規模な投資をためらっている紹介していました。
また、少なくとも ISA は標準化の対象だがセマンティック含め標準化するべき項目についても議論の余地があるという話です。
これを読んだ時に、たしかに実行環境が増えていて共通言語としてのバイトコードと意味に仕様が必要になるな思い RFC 9669 をちゃんと読むかという気持ちになりました。
あとで教えてもらったのですがIETF-120のスライド にオフロード機能に関する期待が書かれてました。
BPF/eBPF(bpf) の議事録 を一通り眺めておくのも理解が捗りそうです。
あと ISO が嫌われていて面白かったです。
いままでと変わって結構前(2021)の LWN.net の投稿です。io_uring(7)
io_uring(7) io_uring のリングバッファから eBPF が使えるようにする概念実証とみつかった課題が紹介されています。
eBPF で可能なことが広がるおもしろそうな話です。
これに類することは記事よりさらに1年くらい前に ScyllaDB も記事 にしてました。
しかし記事では、ケイパビリティの整理や複雑になる実装、そして予期困難なレイテンシーなど大きな課題も紹介していました。
少しずれますが io_uring と eBPF 関連では RingGuard: Guard io_uring with eBPF (COMM eBPF'23) という論文がでています。
これは io_uring に eBPF をアタッチさせてセキュリティや監査を実現した実装みたいです。
背景には io_uring は seccomp の標準的な仕組みをバイパスしてしまいセキュリティが働かないこと、まだ若くセキュリティインシデントが多いことを挙げていました。
カーネルパッチを待たずに素早く対処できるというのが提案手法のメリットのようでした。
自分は seccomp で素直に io_uring を扱うのがダメなのか理解できてません。パラメータなど詳細をみないと対応できないからなんですかね。そこを調べたり読み直したりしないと評価できないなと思っています。
論文を読んでいると io_uring(7) のセキュリティ関連記事( LWN.net, CVE )へのリンクが多くあり背景の理解からやっていこうと思いました。
おわり
今回はすこし将来になりそうな話題を拾いましたが eBPF の周辺はまだまだ広がりそうで楽しかったです。
概念実証の先ではレイヤをバイパスする時に失われるメタ情報の補完やセキュリティ対応が待ち構えているのもよく実感できます。
XRP などは実装も公開されています。読んだり実験したりすれば eBPF やセキュリティの議論にフィードバックを返せるようになるかもしれません。
リリース済みの機能や利用事例に限っても eBPF は話題が豊富でキャッチアップは大変ですが楽しい分野です。
eBPF Japan meetup は今後も実施されるようなので興味持った方は参加してみてください。
 Internet GatewayとSaaS Connectionの簡易イメージ
Internet GatewayとSaaS Connectionの簡易イメージ